March was another astonishing month in the world of AI genies with the release of exponentially powerful updates (GPT4 released 14 March; Baidu released Ernie Bot on 16 March), new services and APIs. It is not surprising that by the end of the month, Musk-oil is being poured over the ‘troubling waters’ – will it work now the genie is out of the bottle? Its anyone’s guess and certainly it seems a bit of trickery is the only way to get it back into the bottle at this stage.
Rights
More importantly, and with immediate effect, the US Copyright Office issued a statement on 16 March in relation to the IP issues that have been hot on many lips for several months now: registrations pertaining to copyright are about the processes of human creativity, where the role of generative AI is simply seen as a toolset under current legal copyright registration guidance. Thus, for example, in the case of Zarya of the Dawn (refer our comments in the Feb 2023 Tech Update), whilst the graphic novel contains original concepts that are attributable to the author, the use of images generated by AI (in the case of Zarya, MidJourney) are not copyrightable. The statement also makes it clear that each copyright registration case will be viewed on its own merit which is surely going to make for a growing backlog of cases in the coming months. It requires detailed clarification of how generative AI is used by human creators in each copyright case to help with the evaluation processes.
The statement also highlights that an inquiry into copyright and generative AIs will be undertaken across agencies later in 2023, where it will seek general public and legal input to evaluate how the law should apply to the use of copyrighted works in “AI training and the resulting treatment of outputs”. Read the full statement here. So, for now at least, the main legal framework in the US remains one of human copyright, where it will be important to keep detailed notes about how creators generated (engineered) content from AIs, as well as adapted and used the outputs, irrespective of the tools used. This will no doubt be a very interesting debate to follow, quite possibly leading to new ways of classifying content generated by AIs… and through which some suggest AIs as autonomous entities with rights could become recognized. It is clear in the statement, for example, that the US Copyright Office recognizes that machines can create (and hallucinate).
The complex issues of the dataset creation and AI training processes will underpin much of the legal stances taken and a paper released at the beginning of Feb 2023 could become one of the defining pieces of research that undermines it all. The research extracted near exact copyrighted images of identified people from a diffusion model, suggesting that it can lead to privacy violations. See a review here and for the full paper go here.
In the meantime, more creative platforms used to showcase creative work are introducing tagging systems to help identify AI generated content – #NoAI, #CreatedWithAI. Sketchfab joined the list at the end of Feb with its update here, with updates relating to its own re-use of such content through its licensing system coming into effect on 23 March.
NVisionary
Nvidia’s progressive march with AI genies needs an AI to keep up with it! Here’s my attempt to review the last month of releases relevant to the world of machinima and virtual production.
In February, we highlighted ControlNet as a means to focus on specific aspects of image generation and this month, on 8 March, Nvidia released the opposite which takes the outline of an image and infills it, called Prismer. You can find the description and code on its NVlabs GitHub page here.
Alongside the portfolio of generative AI tools Nvidia has launched in recent months, with the advent of OpenAI’s GPT4 in March, Nvidia is expanding its tools for creating 3D content –
It is also providing an advanced means to search its already massive database of unclassified 3D objects, integrating with its previously launched Omniverse DeepSearch AI librarian –
It released its cloud-based Picasso generative AI service at GTC23 on 23 March, which is a means to create copyright cleared images, videos and 3D applications. A cloud service is of course a really great idea because who can afford to keep up with the graphics cards prices? The focus for this is enterprise level, however, which no doubt means its not targeting indies at this stage but then again, does it need to when indies are already using DALL-E, Stable Diffusion, MidJourney, etc. Here’s a link to the launch video and here is a link to the wait list –
Pro-seed-ural
A procedural content generator for creating alleyways has been released by Difffuse Studios in the Blender Marketplace, link here and see the video demo here –
We spotted a useful social thread that highlights how to create consistent characters in Midjourney, by Nick St Pierre, using seeds –
🌱 –seeds in Midjourney
What they are, why they're useful, where to find them, & when/how to use them 👇
and you can see the result of the approach in his example of an aging girl here –
Animation
JSFilmz created an interesting character animation using MidJourney5 (which released on 17 March) with advanced character detail features. This really shows its potential alongside animation toolsets such as Character Creator and Metahumans –
Runway’s Gen-2 text-to-video platform launched on 20 March, with higher fidelity and consistency in the outputs than its previous version (which was actually video-to-video output). Here’s a link to the sign-up and website, which includes an outline of the workflow. Here’s the demo –
Gen-2 is also our feature image for this blog post, illustrating the stylization process stage which looks great.
Wonder Dynamics launched on 9 March as a new tool for automating CG animations from characters that you can upload to its cloud service, giving creators the ability to tell stories without all the technical paraphenalia (mmm?). The toolset is being heralded as a means to democratize VFX and it is impressive to see that Aaron Sims Creative are providing some free assets to use with this and even more so to see none other than Steven Spielberg on the Advisory Board. Here’s the demo reel, although so far we’ve not found anyone that’s given it a full trial (its in closed beta at the moment) and shared their overview –
Finally for this month, we close this post with Disney’s Aaron Blaise and his video response to Corridor Crew’s use of generative AI to create a ‘new’ anime workflow, which we commented on last month here. We love his open-minded response to their approach. Check out the video here –
Genies are everywhere now. In this post, I’ll focus on some of the more interesting areas relating to the virtual production pipeline, which interestingly is becoming clearer day by day. Check out this mandala of the skills identified for virtual production by StoryFutures in the UK (published 2 March) but note that skills for using genies within the pipeline are not there (yet)!
Future of Filmmaking
Virtual Producer online magazine published an interesting article, by Noah Kadner (22 Feb), about the range of genie tools available for the film production pipeline, covering the key stages of pre-production, production and post-production. Alongside it, he gives an overview of some of the ethical considerations we’ve been highlighting too. Its nice to the see the structured analysis of the tools although, of course, what AIs do is change or emphasize aspects of processes, conflate parts and obviate the need for others. Many of the tools identified are ones we’ve already discussed in our blogs on this topic, but its fascinating to see the order being put on their use. I think the key thing all of us involved in the world of machinima have learned over the years, however, is that its often the indie creators that take things and do stuff that no one thought about before, so I for one will be interested to see how these neat categories evolve!
Bits and Pieces
It was never going to take long to showcase the ingenuity among users of genies: last month, whilst Futurism was reporting on the dilemma of ethical behaviour among users who have ‘jailbroken’ the ChatGPT safeguards, MidJourney was busy invoking even more governance over its use. MidJourney says its approach, which now bans the use of words about human reproductive systems, is to ‘temporarily prevent people from creating shocking or gory images’. All this very much reminds me of an AI experiment carried out by Microsoft almost seven years ago as we release this post, on 24 March 2016, and of the artist Zach Blas’ interpretation of that work showcased in 2017, called ‘Im here to learn so :))))))‘.
For those without long(ish) memories, Blas’ work was a video art installation visualizing Tay, which had been designed by Microsoft as a 19 years old American female chatbot. As an AI, it lived for just one day on its social media platform where it was subjected to a tyranny of misognyistic, abusive, hate-filled diatribe. Needless to say, corporate nervousness in its creative representation of the verbiage it generated from its learning processes resulted in it being terminated before it really got going. Blas’ interpretation of Tay, ironically using Reallusion’s CrazyTalk to animate it as an ‘undead AI’, is a useful reminder of how algorithms work and the nature of humanbeans. The link under the image below takes you to where you can watch the video of Tay reflecting on its experience and deepdreams. Salutary.
Speaking of dreams, Dreamix is a creative tool that uses an input video with a text prompt to create some other video output. In effect, it takes the user through the pre-production, production and post-production process in just one sweep. Here’s a video explainer –
In a not dissimilar vein, ControlNet takes an image generated in Stable Diffusion and applies a controller to inpaint the image in any style you’d like to see. Here’s an explainer by Software Engineering Courses –
and here’s the idea taken to a whole new level by Corridor Crew in their development of an anime film. The explainer takes you through the process they created from scratch, including training an AI –
They describe the process they’ve gone through really well, and its surely not going to be too long before this becomes automated with an app you can pick up in a virtual store near you.
Surprise, surprise, here is RunwayML’s Gen-1: not quite the automated app actually, but pretty close. Runway has created an AI that takes video input and an image with a style you would like to apply to it and with a little bit of genie magic, the output video has the style transferred to it. What makes this super interesting, however, is that Runway Studios is now a thing too – it is the entertainment and production division of Runway and aims to partner with ‘next gen’ storytellers. It has launched two initiaties worth following: an annual AI Film Festival, which just closed its first call for entries. Here’s a link to the panel discussion that took place in New York on 1 Mar, with Paul Trillo, Souki Mehdaoui, Cleo Abram and Darren Aronofsky –
The second initiative is its creative grants for ‘aspiring filmmakers from various backgrounds who are in need of production support’. On its Google formlet, it states grants take various shapes, including advanced access to the latest AI Magic Tools, funding allocations, as well as educational resources. Definitely worth bearing in mind for your next step in devising machine-cinema stories.
Genious?
Whilst we sit back and wait for the AI generated films to bubble to the top of our algorithmically controlled YouTube channel, or at least, the ones where Google tools have been part of the process, we bring you a new-old classic. Welcome to FrAIsier 3000. This is described as a parody show that combines surreal humor, philosophical musings and heartfelt moments from an alternate dimension, where an hallucinogenic FrAIsier reflects on the mysteries of existence and the human condition. Wonderful stuff, as ever. Here’s a link to episode 1 but do check out episode 2, waxing lyrically on ‘coq au vin’ as a perfect example of the balance between the dichotomy of discipline and carefreeness (and our feature image for this post) –
If you find inspiring examples of AI generated films, or yet more examples of genies that push at the boundaries of our virtual production world, do get and touch or share in the comments.
Now the AI genie is in full flight, we’ve been anticipating the exponential growth in interest in creative applications – and also in the ethical and moral questions being asked. This month, we have not been disappointed! We start our review with some of the tools we’ve seen emerge and finish with a review of the legal situation that’s been taking shape over the last month, since our January update on the topic.
It takes Text-to-???
It seems most of the online world has bought into the hype around ChatGPT, and who can blame folks for wanting in on the action – it reached a million users faster than any platform has previously in the history of the internet ie., 5 days. Whilst it appears that Google and others have for once been caught sleeping on the job, Microsoft has stolen a march and helped OpenAI monetize its premium chat service for a mere $20/month (just a week after the extended partnership was announced and only if you are US-based) from which each partner will no doubt benefit massively. In the meantime, there has been a huge number of Chrome browser extensions launched based on ChatGPT for everything from search using voice commands, article summaries, writing Excel formulae, email assistance, LinkedIn comments management, to SEO optimization and a heap of other useful-ish applications. Go to the Chrome web store and search for the ones that will help with your creative pipeline – I’m sure someone somewhere will have thought of it before you.
I found a few uses for the YouTube summary assistants of which there are a couple of options, this being one (by Glasp) –
After adding the extension, it took a couple of seconds in total to transcribe the video, copy the text into my ChatGPT account and summarize an hour long interview I did with John Gaeta last year. This is the summary of that interview, which is a pretty good overview of what was discussed albeit the first part is almost verbatim from the intro –
The video is an interview with John Gaeta, who is known for creating the famous bullet time shot in the “Matrix” films. He won the Best Visual Effects Oscar for his work on the Matrix and co-founded Lucasfilm’s immersive entertainment division called ILMxLAB, where he acts as the Executive Creative Director. In the interview, he talks about his experience in creating a demo for the Sony PlayStation super computer, which was shown at Siggraph in 2000. He also mentions his interest in building big and complicated projects while also making entertainment products. Gaeta explains how the bullet time shot was a result of a philosophy they had during the Matrix trilogy of creating methods that might be used if one was making virtual reality. He also touches on how the rise of the internet and gaming helped audiences comprehend the shot better and how it carried on the underlying premise of the Matrix itself. (ChatGPT)
and here’s the full interview –
If, like me, you’re after nuggets and detail (my day job is as a researcher), then this won’t really help you but if you just want to get a sense of what’s being discussed, and you’re reviewing lots of material from various channels, or want a quick summary for promo, then its really a great way to generate an overview.
Creatively, though, we’re far more interested in the potential for Text-to-Otherstuff, such as 3D assets, video and 3D environments. Towards that end, although targeting game asset dev, Scenario.gg is a proposition (launched in 2019) that closed a round of significant seedcorn investment in January. With its creators’ backgrounds in gaming, AI and 3D technology, Scenario’s generative AI creates game assets using both image and text promps, albeit currently outputs are 2D images (see below). Its aim is to support creation of high fidelity assets, 3D models, sounds & music, animations, environments and more, based on users’ uploads of their own content (image and text description). The ownership model on generated content is interesting, which pushes the IP issue back to users since only images you have the right to use can be uploaded.
Scenario believes its product will cut creative production time for game artists (those who choose to work with AI). It surpassed .5M created images on 21 January, so is clearly gaining momentum. This is an interesting development, given comments by Aura Triolo (an Independent Games Festival 2023 judge and animation lead at Ivy Road) in an article covering AI devs for metaverse and games here (by Wagner James Au on his New World Notes blog, published in mid December). Triolo makes the point that time savings probably won’t be worth the effort given how much additional work is required to refine 3D models that AI generates, particularly in AAAs (as in the use of AI for procedural generation). That may well be true in a context where automation tools have been used for some time but this type of toolset will surely benefit thousands of indies, and not just in gaming but also machinima and virtual production. Time will tell.
source: Scenario in Techcrunch
Meta AI has published a paper that discusses taking their text-to-video (MAV) generator one step further to 4D (NeRFs or neural radiance fields), referring to it as MAV3D (Make-a-Video-3D). It optimizes scene appearance, density and motion consistency from text-to-video, generates a view from any camera location and angle and can be composited into any 3D environment. MAV3D does not require any 3D or 4D data. It is not yet available as a tool to use but here’s the paper to read. We look forward to hearing more about this in due course.
Text-to-fashion? Well, maybe not just yet, however ReadyPlayerMe, which is a cross platform avatar creator, has a new feature on its recently launched ‘labs’ web platform. Currently in beta and free, it allows you to customise avatar outfits using DALL-E’s generative AI art platform for text prompts. After faffing for a few minutes, I created this (but the hair is still a mess!) –
Text-to-music is an interesting area. There are no doubt going to be lots of training issues emerge with this type of AI, however, what fascinates me with Google‘s MusicLM is the ability to generate music from rich captions, using a ‘story mode’ (with a sequencer) and even from descriptions of paintings, places and epochs. I don’t think I’ve ever heard anything quite like the piece it generated for Munch’s The Scream, using a description by Iain Zaczek – not exactly melodic but certainly evocative of the artwork. It will also let you hum something and then apply a specific instrument to hear it played back, apparently. There is currently no API through which you can test your own ideas, however, but go to the github page here and check out the samples reported in the paper. Google it seems is only making the dataset of MusicCaps comprising 5.5k music-text pairs available, which includes rich text descriptions provided by human experts, and has obviously decided to let someone else create the API and take the rap with it. It will no doubt be one of many in due course, but there are some great ideas presented in the paper worth checking out.
Curation and Discovery
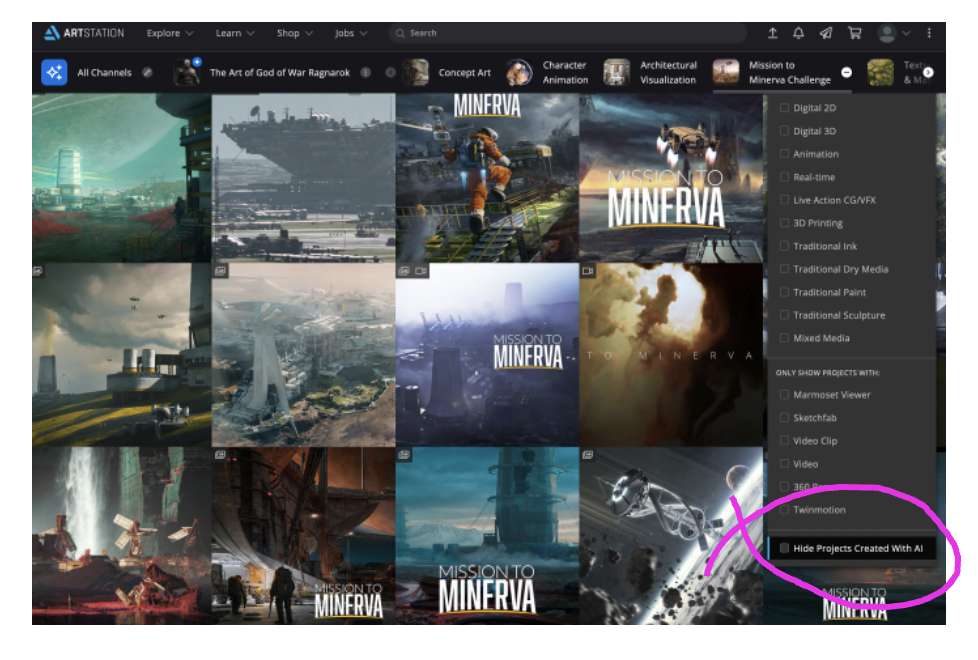
Curating content is one of the perenial problems of the internet – and its a problem that is getting more challenging because even with so much effort being put into the creator toolsets, no one is really paying much attention in the creator context of how work can be discovered (unless of course there is advertising embedded in it, which is a whole different agenda). One can only hope that when advanced AIs are embedded within search engines, new opportunities for content discovery will emerge – sadly, however, I suspect this will result in an even deeper quagmire, leaving it to the key platforms to find a way through. Related to which, Artstation has now improved its AI search and browsing filters – it can hide artwork generated with AI in search and marketplaces and thereby ‘make it easier to discover and connect with creators most relevant to you’, but strangely it doesn’t promote only work created with AI in search.
On the matter of curation, a website for AI generators has launched, called All Things AI – AI developers can submit their tool to the site for its potential inclusion. The site has been developed by Rick Waalders, and whilst there are numerous AI tools and services on the site, there’s not much information yet about its creator or indeed reviews of the AIs themselves. If the site takes off, it might just be the place to find the apps you want – time will tell. Until then, blogs such as Pinar Seyhan-Demirdag‘s Medium post, dated 11 January, are great sources for curated content. In this post, Pinar lists more than a dozen 3D asset and scene generation models – a very useful summary, thanks. Now, what we really need is a Fandom wiki for AIs…!
The Legals are Circling
What a busy month it has been in lawyerland.
On 17 January, in San Francisco US, a class action suit was filed on behalf of three artists. It claims that Stability AI’s Stable Diffusion and DreamStudio, MidJourney and DeviantArt have colluded in the use of an AI that has been trained on scraped content that infringes the rights of copyright holders (the AI being created by a company called LAION which has connections to Stability AI) and that the results of its application by users has a detrimental impact on the artists making profit from their own work as a consequence. One of the legal team has written a detailed blog about the action here, and here is the link to the action, should you want a quick scan through its 46 pages. The following day, 18 January, Getty Images stated that it has commenced proceedings against Stability AI in the High Court of Justice in London –
… Stability AI infringed intellectual property rights including copyright in content owned or represented by Getty Images. It is Getty Images’ position that Stability AI unlawfully copied and processed millions of images protected by copyright and the associated metadata owned or represented by Getty Images absent a license to benefit Stability AI’s commercial interests and to the detriment of the content creators.
Getty Images believes artificial intelligence has the potential to stimulate creative endeavors. Accordingly, Getty Images provided licenses to leading technology innovators for purposes related to training artificial intelligence systems in a manner that respects personal and intellectual property rights. Stability AI did not seek any such license from Getty Images and instead, we believe, chose to ignore viable licensing options and long‑standing legal protections in pursuit of their stand‑alone commercial interests.
No more specifics are available on the Getty case. The latter comments are particularly interesting, however, given its stance with creative contributors whom it has banned from uploading AI generated content, something we highlighted in our December blog post.
On the US class action, notwithstanding the technicalities of its description of how the AI works (which some have already questioned as being incorrect), the action is primarily about two aspects of copyright infringement – one related to a company which is ‘licensing images’ for use in training the AIs (that a couple of the image generating companies are using); the other is the specific use of an artist’s name to generate an image ‘in the style of …’ which suggests that person’s specific work, tagged presumably with their name, has been used without their permission to train the AI. Those using the images ‘in the style of x’ are referred to as ‘imposters’ whom it is being argued are contributing to the fake economy (which different governments are currently trying to control). The suit is not against the imposters but those who allow imposters to profit.
The action holds that the companies ‘scraping’ the images (which is a metaphor for how images are actually used in the diffusion process) could provide a means to seek permission from those artists used but it has not done so because it is ultimately expensive and takes time to do. The action is for compensation of damages for lost revenue and damage to brand identity of artists. The premise for this is that the companies being sued are generating huge amounts of money that is not finding its way to those contributors whose work is used in the training processes. The money flows are therefore the areas where the ‘fair use doctrine’ is being brought to bear.
The substantive legal issue, however, seems to centre on transformative works (from derivative works). Corridor Crew has produced a nice summary in a video with California State attorney Jake Watson explaining how AI probably DOES transform the work sufficiently for its use of copyrighted images to constitute FAIR USE. So it still comes down to what fairness means in terms of money flows, ultimately. Here’s the video –
And for a line by line commentary on another perspective of the class action blog post by one of the artists’ legal team, a response has been created by a group of ‘tech enthusiasts uninvolved in the case, and not lawyers, for the purpose of fighting misinformation’. I hesitated to include this link, especially since the author/s are anonymous and the contact link is to an ancient Simpsons video sniping at profiteering lawyers, but it makes some interesting points and is well referenced.
It generally sounds like there is a fix to this problem, and its one we’ve highlighted in previous posts on this topic, where AI generator platforms pay artists to use their work… oh, wait, isn’t Shutterstock already doing that, working with OpenAI’s DALL-E? Yes, and here is its generator – it pays the artists (I couldn’t find how much) and users pay for the images downloaded ($19/month for 10 images or 1 video). The wicked problem here, Techcrunch argues, is will folks be willing to pay for AI generated artwork, suggesting yes they will if the generator service has the best selection, pricing, discovery, and overall experience for the user and the artist. And, DreamStudio Pro is already a paid for service that folks are using.
Or, you can opt out of your art being included in Stable Diffusion’s AI, using the third party HaveIBeenTrained web service by an artist-based startup called Spawning. It looks as though there have been a few problems using this service according to the comments, such as being able to tag anyone’s imagery, but even more surprising was that not many seem to have viewed the support video in comparison to all the hoo-haa in the media on this topic. Check out this video –
Alternatively, you can just head over to LAION’s website and opt out there (scroll to the bottom of the page), following the long-winded GDPR processes under the EU reparation system.
In the meantime, Artstation has updated its T&Cs to make it clear that scraping, reselling or redistributing content is not permited and furthermore, it has committed to not licensing content to AI generator platforms for training purposes. Epic’s stance is always interesting to note, but its business model is not tied to just this one type of offer as the other platforms are.
And finally on the legals this month, we were intrigued to note that the US Copyright Office appeared to have cancelled the registration of the first AI generated graphic novel, called Zarya of the Dawn (our feature image for this article, by Kristina Kashtanova), claiming it had ‘made an error’ in the registration process… turns out that they are still ‘working on a response’, stating their portal is in beta. This was not before the artist had made an extensive response to the apparent cancellation through her lawyer, Van Lindberg. Its worth taking a few minutes to read the claims for originality, using MidJourney to support her creative processes, here. In sum, the response states –
… the use of that tool does not diminish the human mind that conceived, created, selected, refined, cropped, positioned, framed, and arranged all the different elements of the Work into a story that reflects Kashtanova’s personal experience and artistic vision. As such, the Work is the result of human authorship…
So this is yet another situation where the outcome is awaited. More next month for sure!
A month is apparently a VERY long time in the world of artificial intelligence… since our last post on this topic, released at the beginning of December, we’ve seen even more amazing techs launch.
ChatGPT
This is another creative AI from the OpenAI stable (also creator of DALL-E 2) that produces text in a conversational way. ChatGPT is capable of answering pretty much any question or request you care to throw at it, and the answers are actually quite robust if a little fuzzy around the edges at times (don’t rely on it for anything critical, in the words of Sam Altman, OpenAI CEO). Here’s an example I asked it for this post, using the prompt: ‘In the style of H P Lovecraft, write a description of a character for someone who hunts the Chluthu’
Response:
Professor Alistair Dunsmore was a man obsessed. For years, he had devoted his life to studying the mysteries of the cosmos, and in particular, the myth of the Chluthu.
A brilliant but troubled man, Dunsmore was driven by a need to uncover the truth about the terrifying creature that lurked beyond the veil of our known universe. He had spent years pouring over ancient texts and forbidden tomes, piecing together the scattered clues that hinted at the Chluthu’s existence.
And then, one fateful day, he discovered something that would change his life forever. A fragment of an ancient artifact, imbued with otherworldly powers, that seemed to hold the key to finding the Chluthu.
Dunsmore knew that he had to have it, no matter the cost. And so he set out on a quest to track down the artifact and unlock its secrets. He traveled to the far corners of the earth, braving dangers and braving the unknown, all in the pursuit of his ultimate goal.
Some say that Dunsmore was mad, driven to the brink by his obsession. But to those who knew him, he was a hero, a brave and brilliant man who dared to stare into the darkness and face the horrors that lay within.
That’s impressive – and it took just seconds to generate. It has great potential to be a useful tool for scriptwriting for stories and character development that can be used in machinima and virtual productions, and also marketing assets you might use to promote your creative works too!
And as if that isn’t useful enough, some bright folks have already used it to write a game and even create a virtual world. Note the detail in the prompts being used – this one from Jon Radoff’s article (4 Dec 2022) for an adventure game concept: ‘I want you to act as if you are a classic text adventure game and we are playing. I don’t want you to ever break out of your character, and you must not refer to yourself in any way. If I want to give you instructions outside the context of the game, I will use curly brackets {like this} but otherwise you are to stick to being the text adventure program. In this game, the setting is a fantasy adventure world. Each room should have at least 3 sentence descriptions. Start by displaying the first room at the beginning of the game, and wait for my to give you my first command’.
The detail is obviously the key and no doubt we’ll all get better at writing prompts as we learn how the tools respond to our requests. It is interesting that some are also suggesting there may be a new role on the horizon… a ‘prompt engineer’ (check out this article in the UK’s Financial Times). Yup, that and a ‘script prompter’, or any other possible prompter-writer role you can think of… but can it tell jokes too?
Give it a go – we’d love to hear your thoughts on the ideas it generates. Of course, those of you with even more flAIre can then use the scripts to generate images, characters, videos, music and soundscapes. There’s no excuse for not giving these new tools for producing machine cinema a go, surely.
Link requires registration to use (it is currently free) and note the tool now also keeps all of your previous chats which enables you to build on themes as you go: ChatGPT
Image Generators
Building on ChatGPT, D-ID enables you to create photorealistic speaking avatars from text. You can even upload your own image to create a speaking avatar, which of course raises a few IP issues, as we’ve just seen from the LENSA debacle (see this article on FastCompany’s website), but JSFILMZ has highlighted some of the potentials of the tech for machinima and virtual production creators here –
An AI we’ve mentioned previously, Stable Diffusion version 2.1 released on 7 December 2022. This is an image generating AI, its creative tool is called Dream Studio (and the Pro version will create video). In this latest version of the algorithm, developers have improved the filter which removes adult content yet enables beautiful and realistic looking images of characters to be created (now with better defined anatomy and hands), as well as stunning architectural concepts, natural scenery, etc. in a wider range of aesthetic styles than previous versions. It also enables you to produce images with non standard aspect ratios such as panoramics. As with ChatGPT, a lot depends on the prompt written in generating a quality image. This image and prompt example is taken from the Stability.ai website –
source: Stability.ai
So, just to show you how useful this can be, I took some text from the ChatGPT narrative for our imaginary character, Professor Alistair Dunsmore, and used a prompt to generate images of what he might look like and where he might be doing his research. The feature images for this post are some of the images it generated – and I guess I shouldn’t have been so surprised that the character looks vaguely reminiscent of Lovecraft himself. The prompt also produced some other images (below) and all you need to do is select the image you like best. Again, these are impressive outputs from a couple of minutes of playing around with the prompt.
images of Professor Alistair Dunsmore, in his study, searching for the Chluthu, by Tracy & Stable Diffusion
For next month, we might even see if we can create a video for you, but in the meantime, here’s an explainer of a similar approach that Martin Nebelong has taken, using MidJourney instead to retell some classic stories –
Supporting the great potential for creative endeavour, ArtStation has taken a stance in favour of the use of AI in generating images with its portfolio website (which btw was bought by Epic Games in 2021). This is in spite of thousands of its users demanding that it remove AI generated work and prevent content being scraped. This request is predicated on the lack of transparency used by AI developers in training and generating datasets. Instead, ArtStation has removed those using the Ghostbuster-like logo on their portfolios (‘no to AI generated images’) from its homepage and issued a statement about how creatives using the platform can protect their work. The text of an email received on 16 December 2022 stated:
‘Our goal at ArtStation is to empower artists with tools to showcase their work. We have updated our Terms of Service to reflect new features added to ArtStation as it relates to the use of AI software in the creation of artwork posted on the platform.
First, we have introduced a “NoAI” tag. When you tag your projects using the “NoAI” tag, the project will automatically be assigned an HTML “NoAI” meta tag. This will mark the project so that AI systems know you explicitly disallow the use of the project and its contained content by AI systems.
We have also updated the Terms of Service to reflect that it is prohibited to collect, aggregate, mine, scrape, or otherwise use any content uploaded to ArtStation for the purposes of testing, inputting, or integrating such content with AI or other algorithmic methods where any content has been tagged, labeled, or otherwise marked “NoAI”.
You can also read an interesting article following the debate on The Verge’s website here, published 23 December 2022.
example of a logo used by creators on ArtStation portfolios
We’ve said it before, but AI is one of the tools that the digital arts community has commented on FOR YEARS. Its best use is as a means to support creatives to develop new pathways in their work. It does cut corners but it pushes people to think differently. I direct the UK’s Art AI Festival and the festival YouTube channel contains a number videos of live streamed discussions we’ve had with numerous international artists, such as Ernest Edmonds, a founder of the digital arts movement in the 1960s; Victoria and Albert Museum (London) digital arts curator Melanie Lenz; the first creative AI Lumen Prize winner, Cecilie Waagner Falkenstrom; and Eva Jäger, artist, researcher and assistant curator at Serpentine Galleries (London), among others. All discuss the role of AI in the development of their creative and curatorial practice, and AI is often described as a contemporary form of a paintbrush and canvas. As I’ve illustrated above with the H P Lovecraft character development process, its a means to generate some ideas through which it is possible to select and explore new directions that might otherwise take weeks to do. It is unfortunate that some have narrowed their view of its use rather than more actively engaged in discussion on how it might add to the creative processes employed by artists, but we also understand the concerns some have on the blatant exploitation of copyrighted material used without any real form of attribution. Surely AI can be part of the solution for that problem too although I have to admit so far I’ve seen very little effort being put into this part of the challenge – maybe you have?
In other developments, a new ‘globe’ plug-in for Unreal Engine has been developed by Blackshark. This is a fascinating world view, giving users access to synthetic 3D (#SYNTH3D) terrain data, including ground textures, buildings, infrastructure and vegetation of the entire Earth, based on satellite data. It contains some stunning sample sets and, according to Blackshark’s CEO Michael Putz, is the beginning of a new era of visualizing large scale models combined with georeferenced data. I’m sure we can all think of a few good stories that this one will be useful for too. Check out the video explainer here –
And Next…?
Who knows, but we’re looking forward to seeing how this fast action tech set evolves and we’ll be aiming to bring you more updates next month.
Don’t forget to drop us a line or add comments to continue the conversation with us on this.
Everything with AI has grown exponentially this year, and this week we show you AI for animation using different techniques as well as AR, VR and voice cloning. It is astonishing that some of these tools are already a part of our creative toolset, as illustrated in our highlighted projects by GUNSHIP and Fabien Stelzer. Of course, any new toolset comes with its discontents, and so we cover some of those we’ve picked up on this past month too. It is certainly fair to say there are many challenges with this emergent creative practice but it appears these are being thought through alongside the developing applications by those using it… although, of course, legislation is far from here.
Animation
Text-to-image generator Stable Diffusion raised $100M in October this year and is about to release its animation API. On 15 November it released DreamStudio, the first API on its web platform of future AI-based apps, and on 24 November it released Stable Diffusion 2.0. The animation API, DreamStudio Pro, will be a node-based animation suite enabling anyone to create videos, including with music, quickly and easily. It includes storyboarding and is compatible with a whole range of creative toolsets such as Blender, potentially making it a new part of the filmmaking workflow bringing imagination closer to reality without the pain, or so it claims. We’ll see about that shortly no doubt. And btw, 2.0 has higher resolution upscaling options, more filters on adult content, increased depth information that can be more easily transformed into 3D and text-guided in-painting which helps to switch out parts of an image more quickly. You can catch up with the announcements on Robert Scoble’s Youtube channel here –
As if that isn’t amazing enough, Google is creating another method for animating using photographs, think image-to-video, called Google AI FLY. Its approach will make use of pre-existing methods of in-painting, out-painting and super resolution of images to animate a single photo, creating a similar effect to nerf (photogrammetry) but without the requirement for many images. Check out this ‘how its done’ review by Károly Zsolnai-Fehér on the Two Minute Papers channel –
For more information, this article on Petapixel.com‘s site is worth a read too.
And finally this week, Ebsynth by Secret Weapon is an interesting approach that uses a video and a painted keyframe to create a new video resembling the aesthetic style used in the painted frame. It is a type of generative style transfer with an animated output that could only really be achieved in post production but this is soooo much simpler to do and it looks pretty impressive. There is a review of the technique on 80.lv’s website here and an overview by its creators on their Youtube channel here –
We’d love to see anyone’s examples of outputs with these different animation tools, so get in touch if you’d like to share them!
AR & VR
For those of you into AR, AI enthusiast Bjorn Karmann also demonstrated how Stable Diffusion’s in-painting feature can be used to create new experiences – check this out on his Twitter feed here –
Made a quick AR inpainting experiment called We See!
For those of you into 360 and VR, Stephen Coorlas has used MidJourney to create some neat spherical images. Here is his tutorial on the approach –
Also Ran?
Almost late to the AI generator party (mmm….), China has released ERNIE-ViLG 2.0 by Baidu, a Chinese text-to-image AI which Alan Thompson claims is even better than DALL-E and Stable Diffusion albeit using much a smaller model. Check out his review which certainly looks impressive –
Voice
NVidia has done it again – their amazing Riva AI clones a voice using just 30 minutes of voice samples. The application of this is anticipated to be conversational virtual assistants, including multi-lingual assistants and its already been touted as frontrunner with Alexa, Meta and Google – but in terms of virtual production and creative content, it is also possible it could be used to replace actors when, say, they are double booked or poorly. So, make sure you get that covered in your voice-acting contract in future too.
Projects
We found a couple of beautiful projects that push the boundaries this month. Firstly GUNSHIP’s music video is a great example of how this technology can be applied to enhance their creative work. Their video focusses on the aesthetics of cybernetics (and is our headline image for this article). Nice!
Secondly, an audience participation film by Fabien Stelzer which is being released on Twitter. The project uses AI generators for image and voice and also for scriptwriting. After each episode is released, viewers vote on what should happen next which the creator then integrates into the subsequent episode of the story. The series is called Salt and its aesthetic style is intended to be 1970s sci-fi. You can read about his approach on the CNN Business website and be a part of the project here –
Last month we considered the disruption that AI generators are causing in the art world and this month its the film industry’s turn. Just maybe we are seeing an end to Hollywood’s fetish with Marvellizing everything or perhaps AI generators will result in extended stories with the same old visual aesthetic, out-painted and stylized… which is highly likely since AI has to be trained on pre-existing images, text and audio. In this article, Pinar Seyhan Demirdag gives us some thoughts about what might happen but our experience with the emergence of machinima and its transmogriphication into virtual production (and vice versa) teaches us that anything which cuts a few corners will ultimately become part of the process. In this case, AI can be used to supplement everything from concept development, to storyboarding, to animation and visual effects. If that results in new ideas, then all well and good.
When those new ideas get integrated into the workflow using AI generators, however, there is clearly potential for some to be less happy. This is illustrated by Greg Rutkowski, a Polish digital artist whose aesthetic style of ethereal fantasy landscapes is a popular inclusion in text-to-image generators. According to this article in MIT Technology Review, Rutkowski’s name has appeared on more than 10M images and used as a prompt more than 93,000 times in Stable Diffusion alone – and it appears that this is becasue data on which the AI has been trained includes ArtStation, one of the main platforms used by concept artists to share their portfolios. Needless to say, the work is being scaped without attribution – as we have previously discussed.
What’s interesting here is the emerging groundswell of people and companies calling for legislative action. An industry initiative has formed and is evolving rapidly, spearheaded by Adobe in partnership with Twitter and the New York Times called Content Authentication Initiative. CAI aims to authenticate content and is a publishing platform – check out their blog here and note you can become a member for free. To date, it doesn’t appear that the popular AI generators we have reviewed are part of the initiative but it is highly likely they will at some point, so watch this space. In the meantime, Stability AI, creator of Stable Diffusion, is putting effort into listening to its community to address at least some of these issues.
Of course, much game-based machinima will immediately fall foul of such initiatives, especially if content is commercialized in some way – and that’s a whole other dimension to explore as we track the emerging issues… What of the roles of platforms owned by Amazon, Meta and Google, when so much of their content is fan-generated work? And what of those games devs and publishers who have made much hay from the distribution of creative endeavour by their fans? We’ll have to wait and see but so far there’s been no real kick-back from the game publishers that we’ve seen. The anime community in South Korea and Japan has, however, collectively taken action against a former French game developer, 5you. The company used a favored artist’s work, Jung Gi, to create an homage to his practice and aesthetic style after he had died but the community didn’t agree with the use of an AI generator to do that. You can read the article on Rest of World’s website here. Community action is of course very powerful and voting with feet is something that invokes fear in the hearts of all industries.














Recent Comments